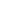
Choose Smart Chatbot
A production-grade Retrieval-Augmented Generation platform that grounds every response in approved knowledge, switches between cloud and local inference, and hands off to humans in real time.
ChooseSmart Chatbot is an AI-powered customer support platform designed to automate customer interactions, provide instant responses, and seamlessly escalate complex issues to human agents.
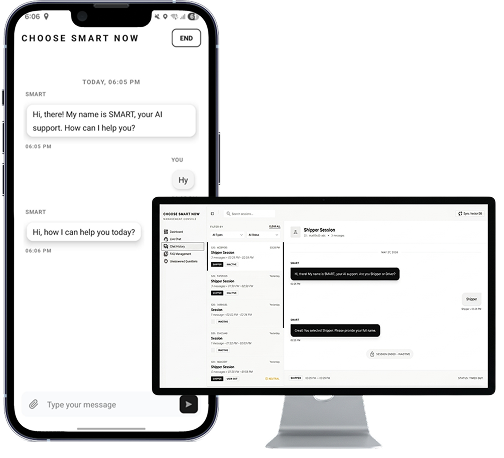
The platform leverages Retrieval-Augmented Generation (RAG), dual LLM architecture, vector search, and real-time agent handoff to deliver accurate and context-aware support experiences.
The primary goal of the project was to reduce customer response time, improve support efficiency, and minimize hallucinated AI responses while maintaining a human-like conversational experience.
Many businesses struggle to provide fast and accurate customer support, especially when handling a large number of customer queries daily. Traditional support systems often rely heavily on human agents, which increases response time, operational costs, and workload.
Traditional customer support systems faced several challenges:
The client required a scalable AI support solution capable of:
To solve these challenges, the ChooseSmart Chatbot platform was developed using RAG architecture, vector search, and real-time AI-to-human escalation to provide a smarter and more reliable customer support experience.
KPIS Pvt. Ltd. engineered ChooseSmart as a production-grade Retrieval-Augmented Generation platform that grounds every answer in approved knowledge and connects users to human agents in real time.
Each question is expanded into multiple query variants, matched against the knowledge base using embedding-based similarity search, then deduplicated and ranked before a language model composes a source-cited answer using configurable relevance thresholds.
A config-driven design supports OpenAI GPT-4o and Llama 3.1, plus OpenAI text-embedding-3-large and Ollama nomic-embed-text, so the platform can switch between cloud and local inference to balance cost, performance, and data privacy.
FAQ embeddings are stored in Qdrant with CRUD auto-sync, five-query-variant vector search, cosine-similarity filtering, and irrelevant-question pre-classification to keep responses on-topic and trustworthy.
Intent classification detects when a query needs a person, and WebSocket / Socket.IO instantly connects the customer to a live support agent without losing context.
Redis manages session lifecycles with time-to-live (TTL) controls, while MongoDB archives full transcripts for analytics, quality review, and transcript delivery.
A short list, in plain language, of what the production platform actually does on day one.
Accurate, source-cited responses generated only from verified knowledge.
Each question is broadened into several variants and the best-matching context is selected and ranked.
Cloud (OpenAI) and local (Ollama / Llama 3.1) inference, switchable by configuration.
FAQ embeddings with auto-sync, cosine-similarity filtering, and irrelevant-question pre-classification.
Real-time WebSocket / Socket.IO handoff from AI to a human agent when intent classification flags it.
Redis TTL-based session control for reliable, time-bound conversations.
MongoDB storage of conversations for reporting, auditing, and continuous improvement.
Answers display the knowledge sources used, increasing transparency and user trust.
A consistent assistant experience across web and mobile — same brain, same voice.
Modern, modular, and production-tested — chosen to balance accuracy, latency, and data sovereignty.
A six-stage delivery model that keeps engineering, AI, and the client moving as one team.
KPIS mapped support goals, common query types, escalation rules, and data-privacy needs to define feasibility and scope.
The team collected, cleaned, and structured FAQs and documentation into an AI-ready knowledge base for embedding.
Designed the RAG pipeline, dual-LLM provider strategy, Qdrant vector store, and the real-time escalation flow.
Built the retrieval pipeline, intent classification, WebSocket agent handoff, and Redis/MongoDB session and transcript layers.
Tuned relevance thresholds, similarity filtering, and pre-classification to maximise accuracy and minimise hallucinations.
Deployed the platform across web and mobile, with monitoring, analytics, and ongoing optimisation.
Faster answers. Fewer hallucinations. Support that scales without doubling headcount.
Improved response efficiency through round-the-clock answers to common questions.
Reduced repetitive queries on human agents, they now focus only on complex tickets.
Faster information access for customers, with answers backed by verified sources.
Higher answer accuracy and fewer hallucinations thanks to RAG and pre-classification.
Better engagement with in-context escalation to live agents — no repeated questions.
AI-powered support that grows with volume without a matching rise in headcount.
The same questions buyers and engineering teams ask us before signing — written plainly.
KPIS built ChooseSmart, a Retrieval-Augmented Generation (RAG) chatbot that retrieves answers from a verified knowledge base before a large language model generates a response. This grounds every answer in approved content, reduces hallucinations, and lets the system hand complex conversations to human agents in real time when needed.
The platform uses RAG orchestration, OpenAI GPT-4o and Llama 3.1, embedding models, a Qdrant vector store, Redis session management, and MongoDB transcript storage, with WebSocket / Socket.IO real-time agent handoff.
A RAG (Retrieval-Augmented Generation) chatbot retrieves relevant, approved content before generating an answer, so responses are grounded in real sources rather than invented — sharply reducing hallucinations and increasing trust.
Yes. The architecture is domain-agnostic — we adapt the knowledge base, intent flows, and escalation rules to fit healthcare, finance, e-commerce, education, logistics, and more.
It deflects common queries automatically, responds instantly around the clock, reduces support costs, and frees human agents to focus on high-value, complex cases.
Yes. The dual-LLM design switches between cloud models (OpenAI) and local inference (Ollama / Llama 3.1) to balance cost, performance, and data privacy.
KPIS brings real-world RAG architecture experience, a focus on grounded and reliable AI, and end-to-end delivery from design through deployment and ongoing support.
KPIS Pvt. Ltd. designs and deploys custom AI chatbots, RAG systems, and LLM solutions trained on your own knowledge base — accurate, scalable, and ready for production.
 info@kpis.in
info@kpis.in